PRML - Chap 9: Mixture Models and EM - 9.3
By Huy Van
9.3 An Alternative View of EM
Mục đích của thuật toán EM là tìm maximum likelihood cho model có biến ẩn (latent variables). $\mathbf{X}$: dữ liệu quan sát được, $Z$: tất cả biến ẩn, $\mathbf{\theta}$: model parameters thì hàm log likelihood là:
$$ \ln p(\mathbf{X}|\mathbf{\theta}) = \ln \Big\{ \sum_ {\mathbf{Z}} p(\mathbf{X},\mathbf{Z}|\mathbf{\theta}) \Big\} $$
Vấn đề ở đây là vế phải là log của tổng nên cho dù giả sử $p(\mathbf{X},\mathbf{Z}|\mathbf{\theta})$ là hàm mũ thì cũng không thể tìm được nghiệm maximum likelihood (có thể tính thử đạo hàm để kiểm nghiệm :D).
Vì thế nên người ta sử dụng thuật toán EM như sau:
Mục đích là maximize hàm likelihood $p(\mathbf{X}|\mathbf{\theta})$ theo $\mathbf{\theta}$.
- Khởi tạo $\mathbf{\theta}^{old}$.
- E step: Tính $p(\mathbf{Z}|\mathbf{X},\mathbf{\theta})^{old}$.
- M step: Tính $\mathbf{\theta}^{new}$ theo: $$ \mathbf{\theta}^{new} = \mathrm{argmax}_{\mathbf{\theta}} \ Q(\mathbf{\theta},\mathbf{\theta}^{old}) $$
Ở đây: $$ Q(\mathbf{\theta},\mathbf{\theta}^{old}) = \sum_ {\mathbf{Z}} p(\mathbf{Z}|\mathbf{X},\mathbf{\theta}^{old})\ln p(\mathbf{X},\mathbf{Z}|\mathbf{\theta}). $$
- Gán $\mathbf{\theta}^{old} \leftarrow \mathbf{\theta}^{new} $ rồi quay lại bước 2 cho tới khi log likelihood hay giá trị của parameter hội tụ.
9.3.1 Gaussian mixtures revisited
Hàm log likelihood:
$$ \ln p(\mathbf{X}|\mathbf{\pi},\mathbf{\mu}, \mathbf{\Sigma}) = \sum_ {n=1}^N \ln \Big\{ \sum_ {k=1}^K \pi_ k \mathcal{N}(x_ n| \mathbf{\mu}_ k, \mathbf{\Sigma}_ k ) \Big\} $$
Ở đây $\pi_ k$ là hệ số mixture; $\mathbf{\mu}, \mathbf{\Sigma_ k}$ là mean, covariance.
Giờ thì xét bài toán maximizing likelihood cho set {$\mathbf{X}, \mathbf{Z}$}. Sử dụng kết quả từ phần 9.2 thì hàm likelihood sẽ trở thành:
$$ p(\mathbf{X},\mathbf{Z}|\mathbf{\mu},\mathbf{\Sigma},\mathbf{\pi}) = \prod_ {n=1}^N \prod_ {k=1}^K \pi_ k^{z_ {nk}} \mathcal{N}(x_ n|\mathbf{\mu}_ k, \mathbf{\Sigma}_ k)^{z _{nk} } $$
Ở đây $z_ {nk}$ là thành phần thứ $k$ của $\mathbf{z}_ n$. Lấy log ta sẽ được:
$$ \ln p(\mathbf{X},\mathbf{Z}|\mathbf{\mu},\mathbf{\Sigma},\mathbf{\pi}) = \sum_ {n=1}^N \sum_ {k=1}^K z_ {nk} \{ \ln \pi_ k + \ln \mathcal{N}(x_ n|\mathbf{\mu_ k},\mathbf{\Sigma}_ k) \} $$
So sánh với hàm log likelihood cũ thì hàm trên rõ ràng là dễ tính hơn vì trong log không có tổng mà chỉ là 1 hàm mũ theo Gaussian.
Tính theo EM dạng tổng quát ở trên ta sẽ dẫn ra công thức đã tính từ phần 9.2.
9.3.2 Relation to K-means
Xét Gaussian mixture model mà ma trận covariance của thành phần mixture là $\epsilon I$ ($I$ là ma trận đơn vị). Khi $\epsilon \rightarrow 0$ thì kết quả sẽ giống với K-means.
9.3.3 Mixtures of Bernoulli distributions
Nhớ lại phân phối Bernoulli: có D biến nhị phân $x_ i$ với $i = 1, \ldots, D$ mà mỗi biến theo 1 phân phối Bernoulli có parameter $\mu_ i$ thì:
$$ p(\mathbf{x}|\mathbf{\mu}) = \sum_ {i=1}^D \mu_ i^ {x_ i}(1-\mu_ i)^{(1-x_ i)} $$
Ở đây $\mathbf{x} = (x_ 1,\ldots,x_ D)^T$, $\mathbf{\mu} = (\mu_ 1,\ldots,\mu_ D)^T$. Mean và covariance là:
$$ \begin{align} \mathbb{E}[x] &= \mathbf{\mu} \\ \mathrm{cov}[x] &= \mathrm{diag}\{\mu_ i(1-\mu_ i) \} \end{align} $$
Giờ xét mixture của các phân phối Bernoulli:
$$ p(\mathbf{x}|\mathbf{\mu},\mathbf{\pi}) = \sum_ {k=1}^K \pi_ k p(\mathbf{x}|\mathbf{\mu}_ k) $$
với $\mathbf{\mu} = \{\mathbf{\mu}_ 1,\ldots,\mathbf{\mu}_ K \}$, $\mathbf{\pi} = \{\mathbf{\pi}_ 1,\ldots,\mathbf{\pi}_ K \}$ và
$$ p(\mathbf{x}|\mathbf{\mu}_ k) = \sum_ {i=1}^D \mu_ {ki}^ {x_ i}(1-\mu_ {ki})^{(1-x_ i)}. $$
Mean và covariance sẽ trở thành:
$$ \begin{align} \mathbb{E}[x] &= \sum_ {k=1}^K \pi_ k \mathbf{\mu}_ k \\ \mathrm{cov}[x] &= \sum_ {k=1}^K \pi_ k \{ \mathbf{\Sigma}_ k + \mathbf{\mu}_ k \mathbf{\mu}_ k^T \} - \mathbb{E}[x] \mathbb{E}[x] ^T \end{align} $$
với $\mathbf{\Sigma}_ k = \mathrm{diag}\{\mu_ {ki}(1-\mu_ {ki}) \}$.
Giả sử có data set $\mathbf{X} = \{x_ 1, \ldots, x_ N \}$ thì hàm log likelihood sẽ trở thành:
$$ \ln p(\mathbf{X}|\mathbf{\mu}, \mathbf{\pi}) = \sum_ {n=1}^N \ln \Big\{\sum_ {k=1}^K \pi_ k p(x_ n| \mathbf{\mu}_ k ) \Big\} $$
Dễ thấy là lại xuất hiện tổng trong log nên không tìm được nghiệm chính xác. Giờ ta sử dụng EM. Trước tiên ta giới thiệu biến ẩn $\mathbf{z}$ đối với mỗi $x$. Giống với Gaussian mixture, $\mathbf{z} = (z_ 1,\ldots, z_ K)^T$ là biến nhị phân K chiều và chỉ có 1 thành phần là 1, còn lại là 0.
Phân phối điều kiện của $x$ khi biết $z$ là: $$ p(x|\mathbf{z},\mathbf{\mu}) = \prod_ {k=1} ^K p(x|\mathbf{\mu}_ k)^{z_ k} $$
Prior là $$ p(z|\pi)=\prod_ {k=1}^K \pi_ k^{z_ k}. $$
Đầu tiên ta viết ra complete-data log likelihood function:
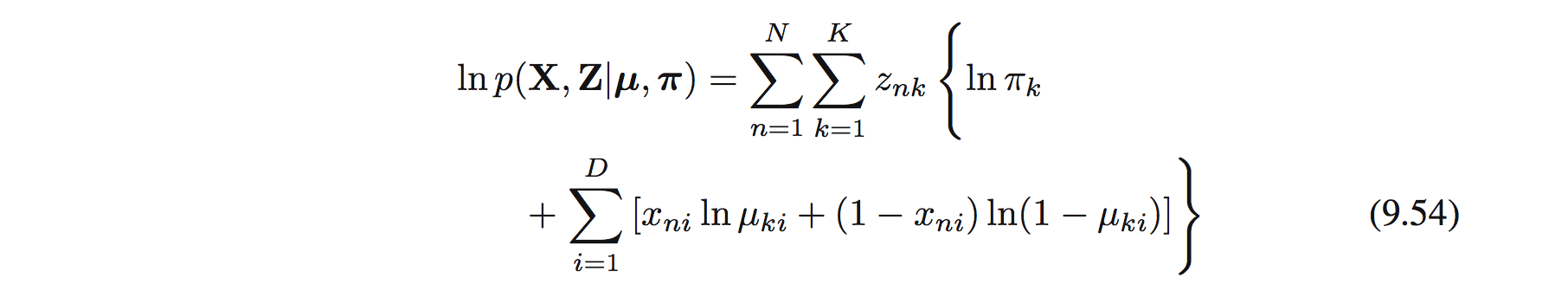
với $\mathbf{X} = \{x_ n \}$ và $\mathbf{Z} = \{z_ n \}$. Tiếp đến ta tính expectation của hàm trên:
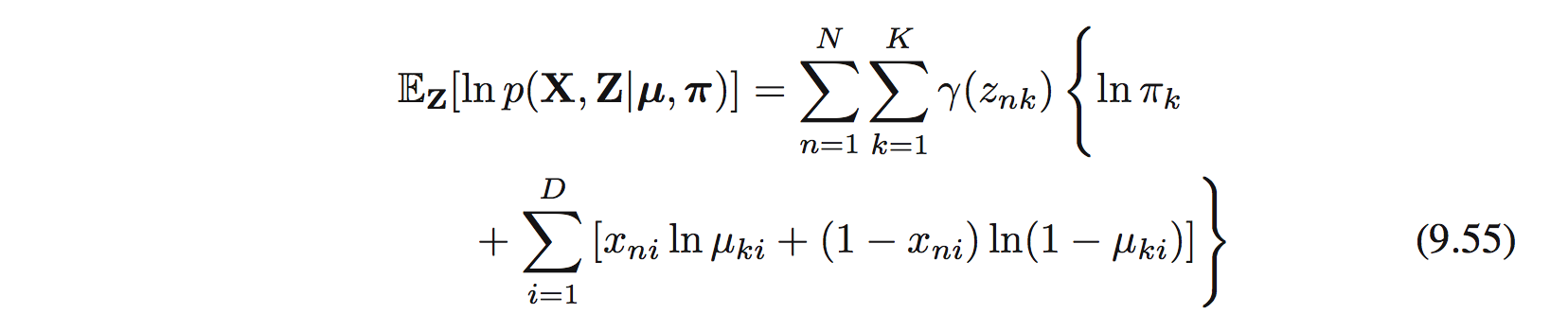
với $\gamma(z_ {nk}) = \mathbb{E}[z_ {nk]}$ là posterior , hay responsibility, của thành phần k cho data point $x_ n$. Trong E step, responsibility sẽ được đánh giá sử dụng định lý Bayes:
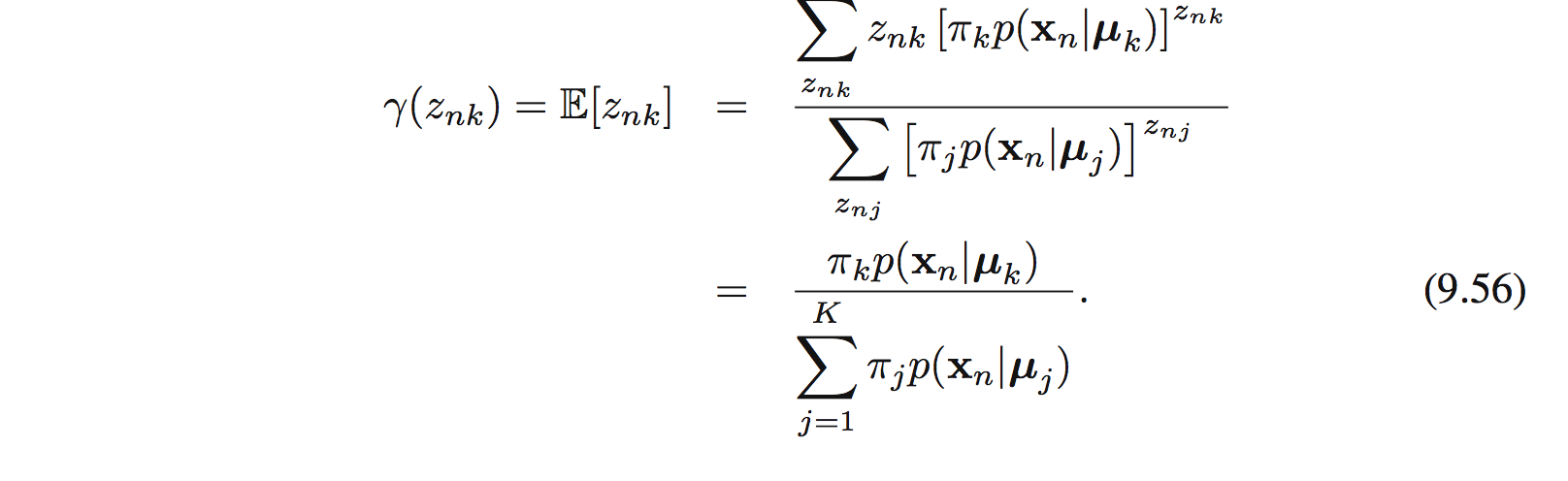
Đặt
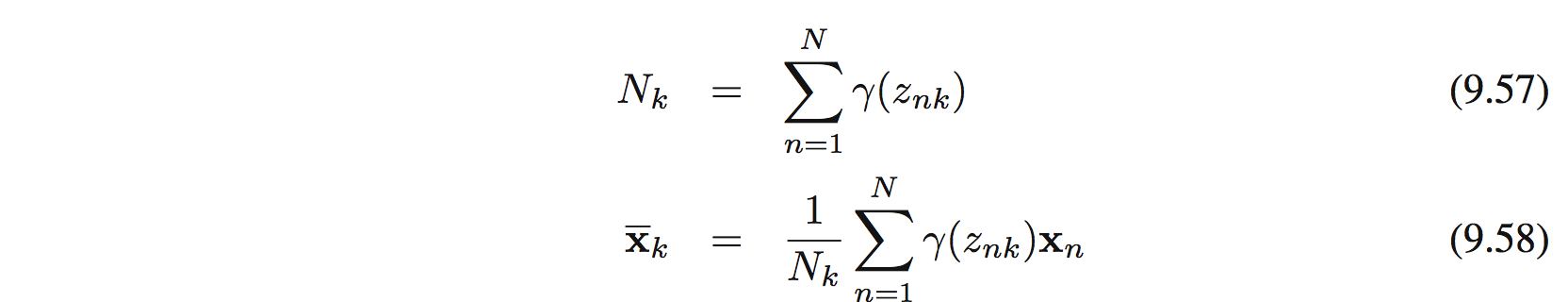
thì $$ \mathbf{\mu}_ k = \bar{\mathbf{x}}_ k $$
Để tìm $\pi_ k$ ta phải sử dụng Lagrange multiplier cho điều kiện $\sum_ k \pi_ k = 1$ và tìm được
$$ \pi_ k = \frac{N_ k}{N} $$
9.3.4 EM for Bayesian linear regression
Sử dụng EM để tính hyperparameters $\alpha$ và $\beta$ trong chương 3.5.2. Tính toán khá dễ dàng và trực quan. Kết quả cụ thể mời tham khảo thêm trong sách.